
tg-me.com/knowledge_accumulator/36
Last Update:
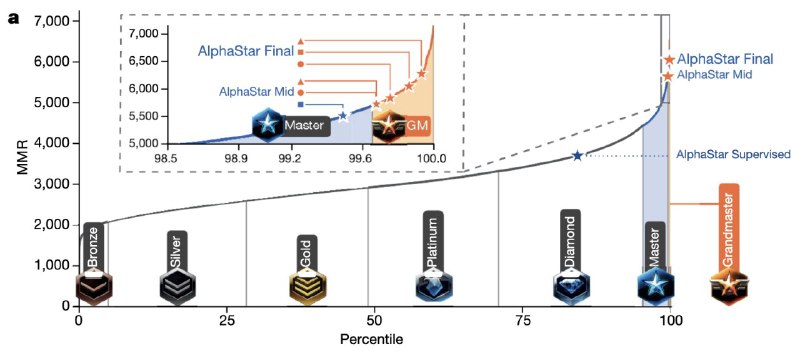
AlphaStar [2019] - мы упёрлись в лимит self-play learning?
С одной стороны, перед нами романтичная история о том, как Oriol Vinyals, будучи в юности крутым Starcraft-игроком, стал ML-исследователем и через полтора десятка лет изобрёл первую Grandmaster-level-систему для Starcraft. В этом подкасте у Lex Fridman он рассказывает много интересного об этом проекте, советую интересующимся.
С другой стороны, при переходе на такой уровень сложности среды мы начинаем видеть пределы такого метода обучения, который используется здесь (он похож на AlphaZero):
1) Без использования человеческих знаний и данных это не работает.
В отличие от Go, в Starcraft вы не можете обучить сильный алгоритм, плавно меняя вашу стратегию, начиная с рандомной. В Go вы можете начать из рандома, потом играть лучше рандома, потом ещё лучше и так далее. В Starcraft вы сразу же натыкаетесь на локальный максимум, в котором вы берёте всех своих стартовых юнитов и идёте бить морду противнику, а не строить базу.
2) Количество данных, которое тут требуется, безумно. Увеличение размерности печально влияет на способность алгоритмов обучаться. Тут мы и видим проблему низкого интеллекта таких систем - они не могут использовать данные так же эффективно, как это делает человек.
В общем, применение прикольное, но технологии у нас пока ещё совсем слабенькие.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/36